Tuning compiler flags for zkVMs
A recent publication Evaluating Compiler Optimization Impacts on zkVM Performance, presented at ZKProof 8, motivated me to test compiler optimizations on the proposed zkEVMs. In this work the compiler is no longer optimizing for the number of instructions on the processor but for the execution trace rows in the AIR table. While the standard optimizations help, we can still tweak the parameters a bit more to push them to better results. As an outcome it was possible to reduce the costs by 10% for ethrex stateless validator running in the ZisK zkVM.
Computation model
We are compiling for architecture riscv64im_zicclsm, which is a bare-metal target. There is no operating system, no standard library and you need to bring your own memory management. Every operation and branch must eventually be proven in the resulting proof of computation.
This instruction set is deliberately simple. There are no extensions like vectorized instructions, but we do have precompiles for computing hash functions. The Zicclsm feature adds support for misaligned loads and stores, more info about why we need it can be found in zkVM standards.
Looking at the ZisK costs table this is also different from conventional CPU. Arithmetic multiplication and division have the same cost. The compiler sometimes rewrites operations using bitwise tricks that are fast on real hardware, but this is counterproductive here. Every instruction pays a fixed cost and multiplication replaced by a series of bitwise operations is strictly worse.
Existing findings and constraints
The mentioned paper correctly identified the most relevant LLVM passes. For the beneficial optimizations it is possible to increase their impact by adjusting the parameters. However it is not easy to disable passes that regress the performance. The previous work patched the LLVM source code to turn off such optimizations, but we will limit ourselves to not doing this for the Ethereum (future) mainnet. If every team developing a zkVM has their own custom compiler the reasoning about the whole system is more complicated.
One clear outcome from the paper is that, applying the opt-level=3 optimizations significantly helps. At this setting, LLVM applies almost every optimization available to it. The tricky part is that some of those passes are harmful for zkVM workloads, and there is no clean --disable-pass <name> flag in the New Pass Manager.
I tried to enumerate the default passes using --print-pipeline-passes, strip the problematic ones, and feed the remainder back manually. However, when benchmarked, that approach regressed. The set of passes LLVM applies internally is apparently not equivalent to the list I fed back. Determining the exact passes seems to be hard. So manually reconstructing the pass pipeline is not a reliable approach.
That being said, there are a few passes that expose a specific disable option flag, but this is more of an exception. Alternatively it is possible to disable some passes by forcing thresholds to zero.
Search for optimal parameters
Okay so, this effectively leaves us with codegen options and llvm-args. There are way too many knobs that we can tweak. I picked the flags, specified in the paper reference implementation, and fed that to an Optuna optimizer commonly used to find hyperparameters in machine learning. The following parameters provided the best results:
--inline-threshold=4749
--inline-instr-cost=1
--inline-memaccess-cost=1
--inline-call-penalty=12
--unroll-threshold=378
--disable-licm-promotion
--licm-versioning-max-depth-threshold=0
--memdep-block-number-limit=2510
--memdep-block-scan-limit=98
--jump-threading-threshold=16
--jump-threading-implication-search-threshold=6
--max-speculation-depth=0
--max-uses-for-sinking=119
--available-load-scan-limit=23
--bonus-inst-threshold=5
--max-num-inline-blocks=6
--loop-interchange-threshold=2
--early-ifcvt-limit=29
--loop-distribute-scev-check-threshold=0
--loop-load-elimination-scev-check-threshold=7
--max-dependences=6
--max-nested-scalar-reduction-interleave=2
The results have a few interesting points. In the previous work it is already known that inlining is the most impactful optimization. That is why the optimizer set the threshold to roughly 21 times the default. Related flags (--inline-instr-cost, --inline-memaccess-cost, --inline-call-penalty) also push the optimizer to prioritize inlining. The flag --max-speculation-depth is pushed all the way to zero because we do not have any branch predictor. Beyond that, the memory dependence limits (--memdep-block-number-limit, --available-load-scan-limit) are adjusted to give LLVM more space for identifying redundant operations.
A few of the other remaining passes lower the thresholds to effectively disable features that the zkVM does not possess. The flag --disable-licm-promotion was added manually because the previous study found that licm was the most harmful pass.
Codegen options
The existing infrastructure in ere-guests already provides:
codegen-units = 1: compiles everything as a single unit, giving LLVM full visibility across the codebase for cross-function optimizations like inlininglto = "fat": performs link-time optimization across the entire dependency treepanic=abort: crashes immediately on error, this eliminates the unwinding logic that would otherwise appear in the trace
I also tested optimising for size with opt-level=s, by reasoning that larger memory means a larger trace to prove. However, size-optimized builds underperformed compared to opt-level=3, suggesting that release passes are still better. Besides that, a popular feature is also target-cpu=native, but that is irrelevant, because we are running a VM not on a native CPU and it already has a specified target.
Results
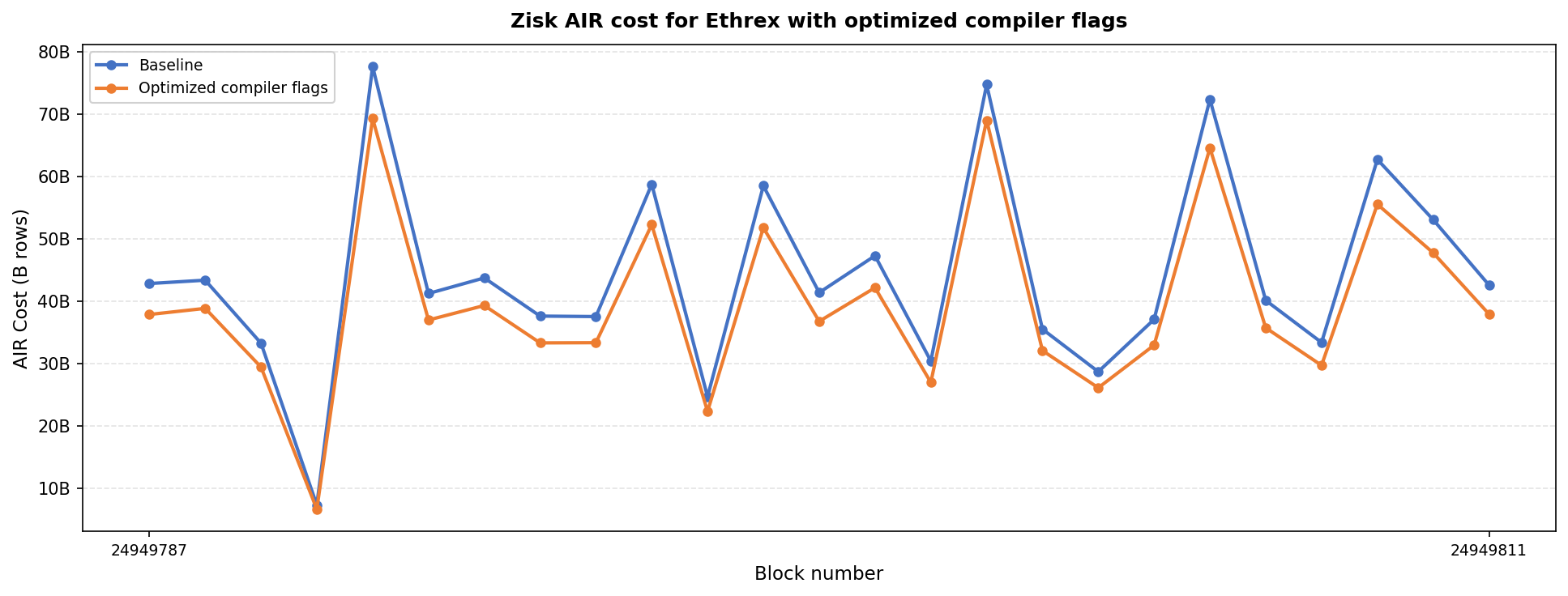
The profiling was done using zkevm-benchmark-workload on mainnet blocks 24949787 - 24949811 and the results show a consistent reduction of the AIR-costs by something over 10%. The average cost per block on the baseline is 44.22B, and the optimized version 39.54B.
Unexplored directions
One could write custom LLVM passes with llvm-plugin. This would allow writing passes tailored to zkVM cost models without forking the compiler, since plugins load at compile time into an unmodified binary. This task seems to be quite complex, and potential improvement was unclear. Besides that it is also possible to give the compiler more context about the program with Profile Guided Optimization. Since we are compiling for bare-metal, this makes the instrumentation more complicated. For sure it is possible to make this work but the optimizations are calibrated for standard CPU cost models and in this case I did not have a reasonable estimate for benefit on the zkVM.
As an outcome, it is possible to get at least 10% improvement on top of opt-level=3, which is very reasonable for no-code change. But as the paper highlighted, the best approach is to use an optimizer to find the most suitable parameters for the specific zkVM.